

Introduction
AI chatbots leverage Generative AI to provide intelligent, context-aware responses. A hybrid approach is often used where predefined intents and FAQ-based responses are prioritized, and the AI model is engaged when no intent match is found. This ensures efficiency while allowing the chatbot to handle complex queries dynamically.
Implementation Process
1. Data Collection
Relevant data sources are gathered to form the chatbot’s knowledge base, including:
- PDFs, webpages, and structured documents such as CSV, JSON.
- Client-specific information relevant to the chatbot’s domain.
- Original documents such as company policies, medical guidelines, or financial information.
2. Data Preprocessing
- De-identification & Image Removal: For privacy compliance, sensitive data is removed from certain datasets.
- Automated Preprocessing: Python scripts process the files, ensuring they only contain de-identified text.
- Standardized Formatting: Text is extracted, cleaned, and structured for indexing, ensuring uniformity.
3. Data Storage
All processed documents are stored in cloud-based storage such as Azure Blob Storage, AWS S3, or Google Cloud Storage.
- Supported formats for indexing include CSV, HTML, JSON, PDF, TXT, and Microsoft Office formats (Word, PPT, Excel).
- Each chatbot implementation has a dedicated storage container to keep knowledge base documents organized.
4. Index Creation
To optimize retrieval efficiency, an index is created using Azure OpenAI Studio, ElasticSearch, VectorDB or other AI search tools.
- The index is built by extracting text, chunking it into manageable sections, and saving these chunks for quick lookups.
- This allows the AI model to search and retrieve relevant information efficiently instead of processing entire documents at runtime.
5. Generative AI Model Deployment
- AI models such as GPT-3.5, GPT-4, or other LLMs are deployed via cloud-based services.
- Onboarding is required to access models, and quota limits can be adjusted based on usage needs.
- Embedding models can be utilized when implementing a vector search index for semantic search capabilities, especially when handling large datasets.
6. API Configuration
Once the search index is set up and the AI model is deployed, the Chat Completions API is configured:
- The chatbot is integrated with the search index and AI model to fetch relevant data.
- API calls are structured to retrieve data, maintain chat history, and generate summarized responses
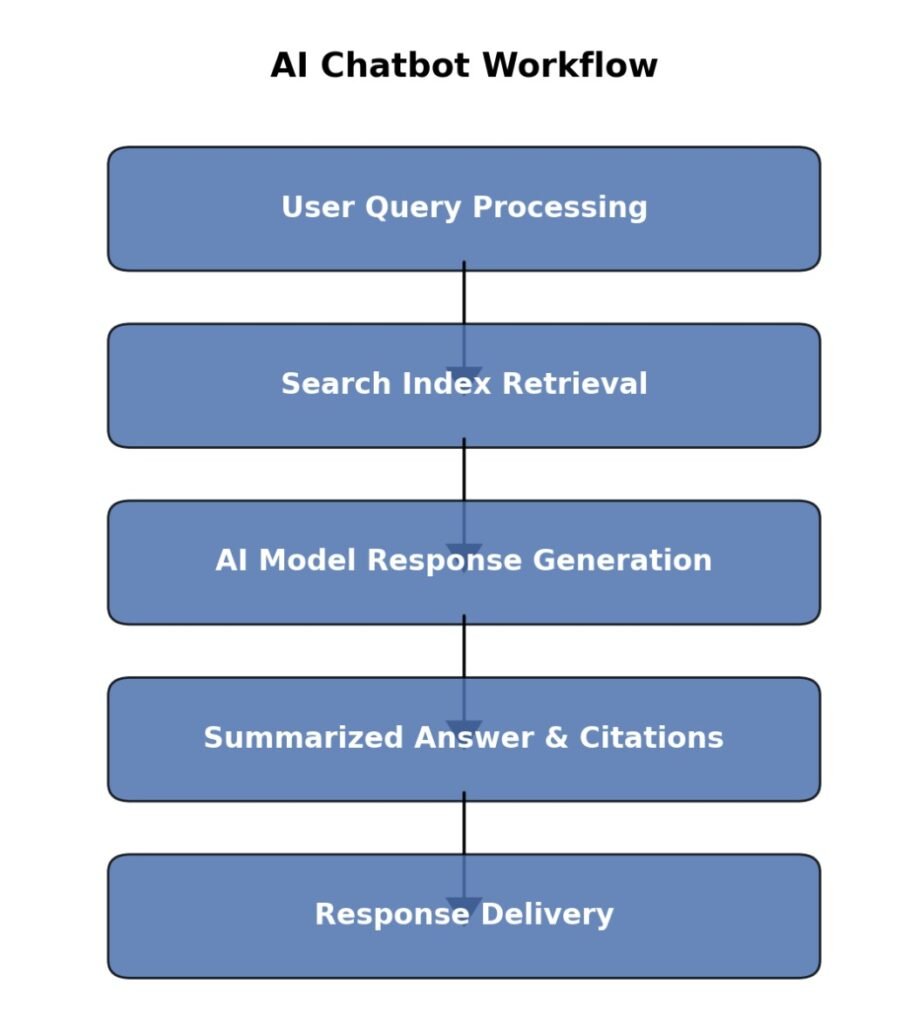
Workflow of the AI Chatbot
- User Query Processing: A user submits a question to the chatbot.
- Search Index Retrieval: The query is sent to the search index, retrieving the top K text chunks based on similarity.
- AI Model Response Generation: The retrieved text chunks, along with the user query and chat history, are fed into the AI model.
- Summarized Answer & Citations: The AI model generates a contextual response, often including references to the original sources.
- Response Delivery: The chatbot provides the generated response, along with links to cited documents when applicable.
Additional Clarifications on how to Efficiently build a chatbot leveraging different services
Document Storage & Access
- Documents are stored in cloud-based storage solutions and indexed in AI search services.
- The AI model retrieves indexed references and provides document URLs for users to access.
- If de-identification is applied, users will still be redirected to the original raw files in storage.
Handling Different File Types
- For HTML files: Instead of providing a document link, the chatbot can redirect users to a live webpage version through a middleware adjustment.
- For PDFs and other static files: Direct access to the indexed document is provided via cloud storage URLs.
Updating the Search Index
- New files are uploaded to cloud storage and must be manually indexed.
- The index must be recreated whenever updates, additions, or deletions occur.
- This process is not fully automated and must be executed manually to ensure updated data is available.
Customizing Search Performance
- Parameters in Azure AI Search or other indexing services can be modified to improve response accuracy.
- Adjustments include chunk size, ranking methods, and indexing frequency to optimize performance.
Quick Replies & Hierarchical Navigation
- Chatbots often use quick reply buttons (pickers) to guide users through hierarchical categories.
- These pickers must be manually configured within the chatbot framework to align with the conversation flow.
Document Storage & Index Mapping
Below is a structured example of chatbot storage, search services, and indexed knowledge bases:
| Category | Resource Group | Storage Account | Container | Search Service | Index Name |
| Healthcare | healthcare chatbot | healthcare docs | health data | healthcare -search – service | healthcare-index |
| Finance | finance chatbot | finance docs | finance data | finance search | finance-index |
| Pharma | pharma chatbot | pharma docs | pharma data | pharma search | pharma-index |
Conclusion
Building an AI chatbot leveraging Generative AI involves data collection, preprocessing, indexing, and AI model deployment. By integrating a robust search retrieval mechanism and API-based response generation, chatbots can provide contextually relevant, accurate, and efficient responses to user queries.
Regular maintenance of the knowledge base and search index ensures chatbot responses stay up to date. Future enhancements may include embedding-based vector search, multimodal AI capabilities, and dynamic knowledge updates, enabling even more intelligent and scalable chatbot solutions.
About Author:

Thrushna Matharasi is a seasoned data and AI leader with extensive experience in engineering and analytics. As the Director of Engineering, Data, and AI at Solera, she leads a global team, driving innovation through predictive analytics, cost optimization, and GDPR compliance automation. Previously, she held key data engineering roles at Digital Turbine, Kasasa, Janus Capital, and BCBS NJ, specializing in cloud migration, real-time analytics, and data pipeline optimization. A published researcher and mentor, Thrushna contributes to AI and ML advancements, chairs technical sessions, and reviews IEEE and Springer papers. Her expertise spans AWS, Snowflake, Kafka, and Looker.
Tech World Times (TWT), a global collective focusing on the latest tech news and trends in blockchain, Fintech, Development & Testing, AI and Startups. If you are looking for the guest post then contact at techworldtimes@gmail.com